The Case for AI That Learns More From Less
For the last decade, the dominant story in artificial intelligence has been scale. The most visible advances have come from models trained on enormous datasets, using enormous compute, running on enormous clusters. This approach has produced systems that would have seemed impossible only a few years ago, and it would be unserious to dismiss what scale has achieved.
But scale has also become a habit.
When a model fails, the instinct is often to make it larger. When performance plateaus, collect more data. When a system struggles to generalize, train longer. When a domain is difficult, throw a bigger architecture at it and hope that enough examples will eventually teach the model what matters.
That logic works best when data are abundant, cheap, and weakly constrained. It is much less convincing in science.
The Problem With Treating Science Like the Internet
A microscopy image is not just an image. A spectrum is not just a sequence. A high-content screening assay is not just a table of features. Scientific data are measurements, and measurements are shaped by instruments, protocols, physical constraints, noise sources, batch effects, sample preparation, and experimental design. The data do not arrive from nowhere. They are produced by a physical system.
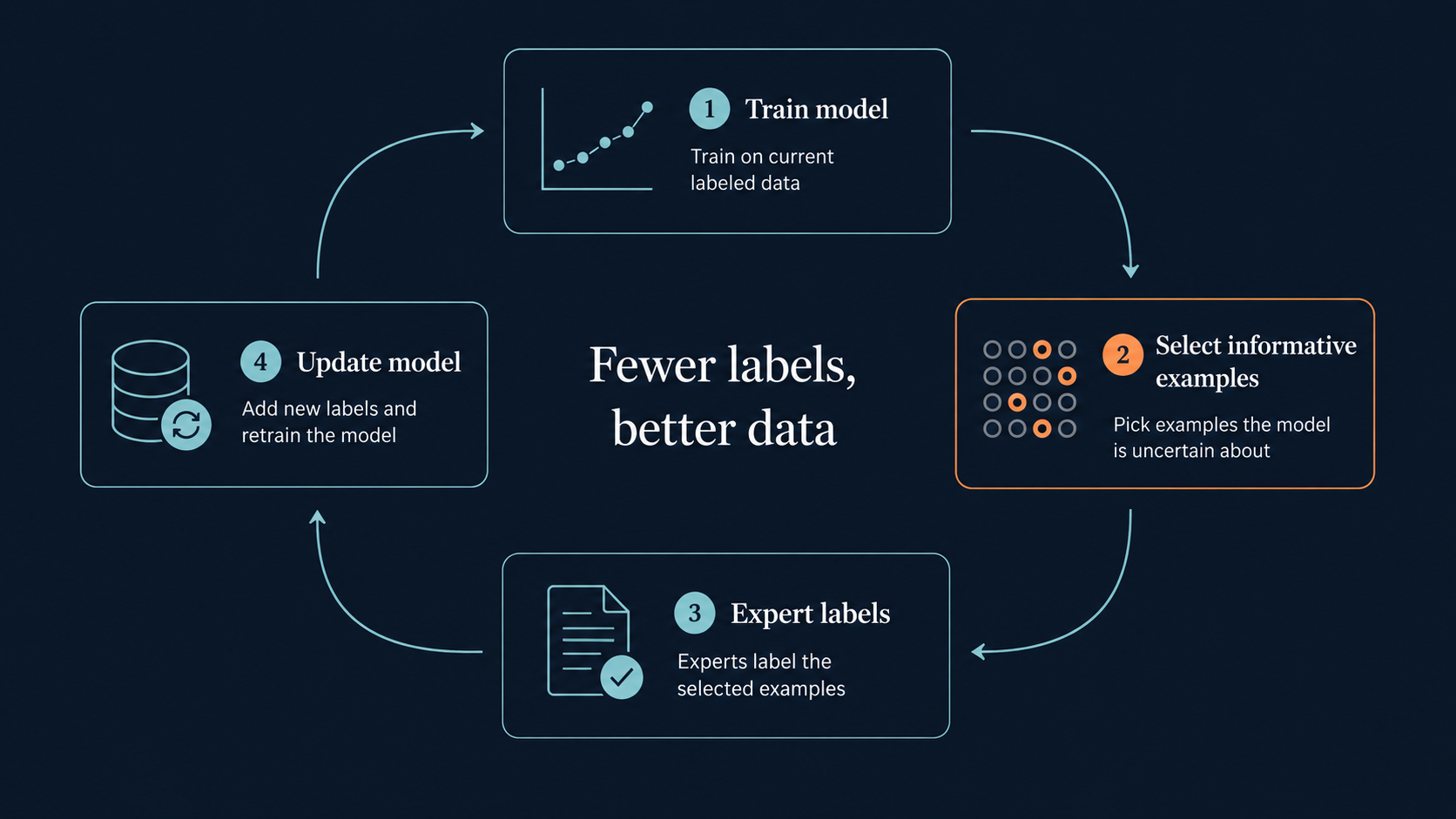
That changes what good AI should look like.
Instead of asking only how large a model can become, we should also ask how much useful structure it can understand before training begins. Can the model learn from the physics of the measurement? Can it separate meaningful biological or material variation from technical noise? Can it adapt to a new instrument, a new batch, or a new laboratory without needing thousands of new labelled examples? Can it become useful before the data collection effort becomes larger than the original scientific question?
These are not secondary details. In science and industry, they are often the difference between an impressive demo and a deployable system.
The infrastructure behind modern AI is already large enough that these questions matter. The International Energy Agency estimates that global data-centre electricity consumption could roughly double from 485 TWh in 2025 to around 950 TWh in 2030, with AI-focused data centres growing even faster over the same period. Stanford’s 2025 AI Index reports a similar pattern from the model side: training compute for notable AI models is doubling approximately every five months. [1, 2]
None of this means that large models are bad. Large foundation models are useful precisely because they are broad, flexible, and capable of absorbing patterns from vast amounts of data. But the success of this paradigm has made it too easy to treat scale as the default answer, even in settings where the real bottleneck is not model size, but data quality, experimental variation, annotation cost, and deployment reliability.
Scientific AI Needs a Different Instinct
In a laboratory or a manufacturing plant, data are rarely free. Labels may require expert judgement. Experiments may take days or weeks to run. Instruments drift over time. Protocols change. Batches differ. The same biological phenotype can look different under slightly different conditions, while a technical artefact can look deceptively meaningful if the model is allowed to learn it.
In these environments, simply collecting more data is not always practical, and training a larger model is rarely the most intelligent response. A better model is not necessarily the one that has seen the most data. It is the one that learns the most from the right data.
This is why data efficiency should be treated as a core property of useful AI, not as a nice optimization added at the end. A data-efficient model can reach strong performance with fewer labelled examples. It can adapt faster when the environment changes. It can significantly reduce the annotation burden on scientists and engineers, making AI usable in places where massive datasets do not exist, and where they may never exist.

There is already a broader shift in machine learning toward this way of thinking. Data-centric AI argues that progress does not only come from changing architectures, but from improving the quality, structure, maintenance, and relevance of the data used to train and evaluate models [3]. Many failures in deployed AI are not caused by a lack of parameters. They are caused by poor labels, hidden leakage, weak metadata, unrepresentative sampling, or a mismatch between the training data and the environment in which the system is actually used.
For scientific imaging, this shift is critical. The central problem is not merely to recognize patterns, but to understand which patterns are real. A model may find correlations in a dataset, but not all correlations are useful. Some reflect biology. Some reflect optics. Some reflect staining variations or plate position. If the model is trained without awareness of these structures, it will become very good at learning the wrong thing.
Where Scientific Priors Become Powerful
A prior is not a way of forcing the model to confirm what we already believe. It is a way of giving the model a better starting point. If we know something about the measurement geometry, the noise profile, the optical system, or the physical constraints of the problem, that knowledge should not sit outside the model. It should shape how the model learns.
The goal is not to replace machine learning with hand-crafted rules. The goal is to stop asking the model to rediscover the obvious from scratch.
Active learning is one practical example of this philosophy [4]. When labels are expensive, the model should not ask for random examples to be annotated. It should identify which examples would be most informative to its current understanding, and request labels only for those.
The same principle applies more broadly:
- If the data are structured, use that structure.
- If the measurement has known invariances (like rotation or translation), encode them.
- If variation is likely to be technical rather than biological, test for it rigorously.
- If a model is intended to work across sites or instruments, evaluate it that way from the beginning.
The Next Phase of AI
This is not a rejection of modern deep learning. It is a more disciplined, physics-informed version of it.
Even in large language models, scale is not as simple as “bigger is better.” Research has repeatedly shown that under a fixed compute budget, model size and training data need to be balanced carefully; smaller models trained optimally on high-quality data consistently outperform much larger, bloated models [5]. The broader lesson is that intelligence is not only a matter of size. It is a matter of allocation: the right model, the right data, and the right training strategy for the task.
In science, that lesson becomes imperative because the data are not interchangeable. A million weakly relevant examples may be less valuable than a much smaller number of well-chosen, well-understood measurements. A large model that performs well on a random validation split is often less trustworthy than a smaller, constrained model that remains stable across batches and instruments.
The next phase of AI should therefore be judged by a broader definition of performance. Accuracy still matters, but it is not enough. We must also care about:
- How many labelled examples were needed?
- How much compute and energy was consumed?
- How robust is the model to technical variation?
- Does it provide scientists with representations they can actually use for downstream decision-making?
A model that is slightly more accurate but requires vastly more data, compute, and manual intervention is not automatically better. In real-world scientific settings, it is usually worse.
This is the case for AI that learns more from less. Not because small models are inherently virtuous, and not because scale has failed, but because the most useful AI systems are the ones that actually fit the physical constraints of the problem they are built to solve. At IFLAI, this is the direction we are building toward: data-efficient, physics-informed AI that learns from the structure of scientific data rather than relying on brute-force scale alone.
The future of AI will not just be bigger. It will be better at learning what matters.
References
- [1] International Energy Agency, “Key Questions on Energy and AI,” 2026.
- [2] Stanford HAI, “2025 AI Index Report,” Research and Development chapter.
- [3] Zha et al., “Data-centric Artificial Intelligence: A Survey,” 2023.
- [4] Settles, “Active Learning Literature Survey,” 2009.
- [5] Hoffmann et al., “Training Compute-Optimal Large Language Models,” 2022.