Why 5 Datapoints Outperforms 50,000: Physics-Informed Priors, Not Fine-Tuning
There's a popular narrative right now in AI: take a massive foundation model, pre-train it on billions of images, then fine-tune it on your specific task with a handful of examples. It's called few-shot transfer learning, and companies across every vertical are claiming it as their competitive edge.
That is not what we do at IFLAI. And here's why.
The Problem with Generic Foundation Models
When OpenAI fine-tunes GPT or Meta fine-tunes LLaMA, they are transferring statistical knowledge. The model has seen so many images of cats that it can recognize a new breed from a few examples. This works because the source domain (internet images) and the target domain (more internet images) share deep statistical structure.
But microscopy is not the internet.
A brightfield micrograph of a HeLa cell bears essentially zero statistical resemblance to an ImageNet photograph of a golden retriever. When you fine-tune a vision model pre-trained on ImageNet to detect cellular morphology, you're asking it to forget everything it learned and start over with your 5 images. The "foundation" is irrelevant. You've just built an extremely expensive few-shot learner that happens to have a good optimizer.
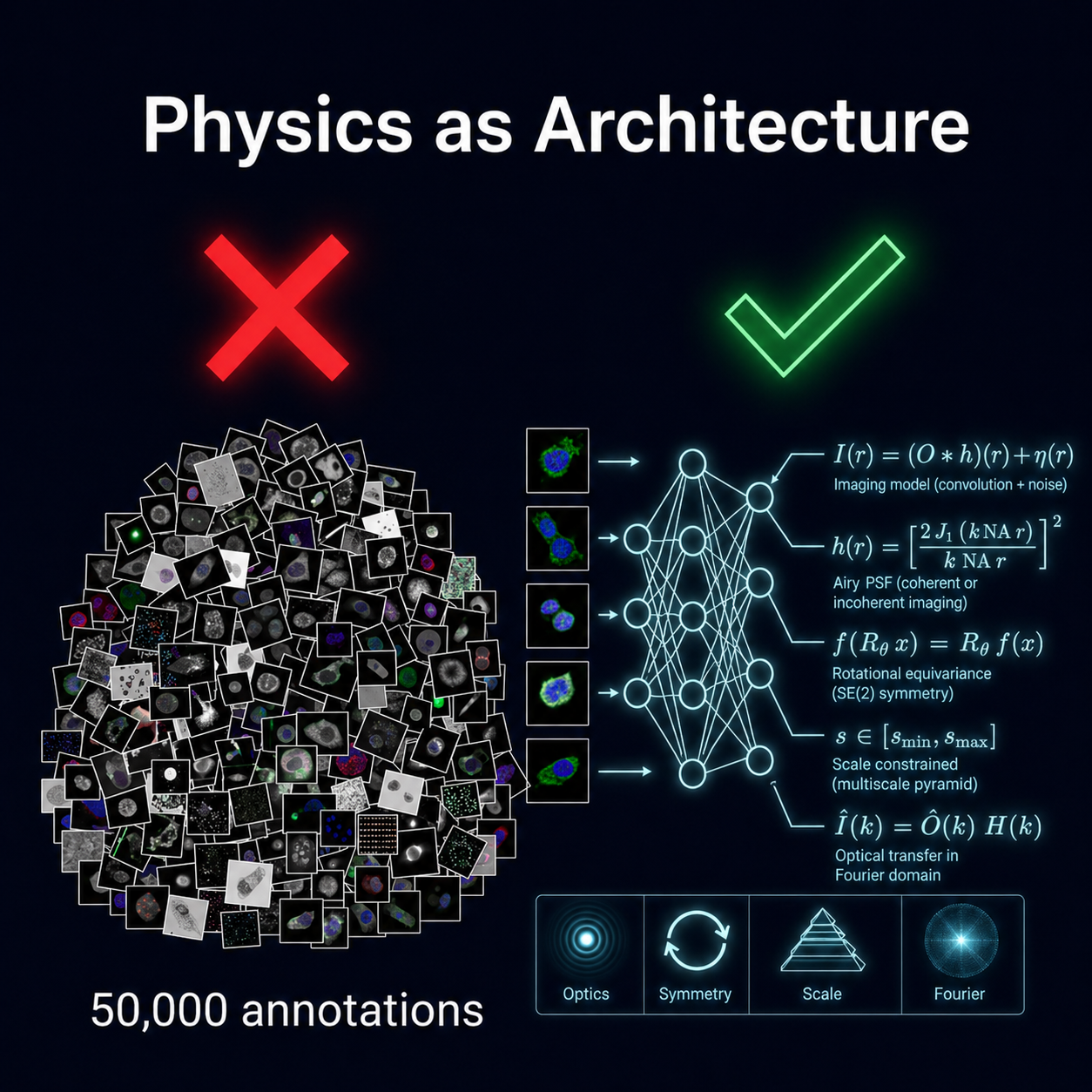
What IFLAI Actually Does: Encoding Physics as Architecture
Our approach starts from a completely different premise. Instead of pre-training on massive generic datasets, we build the laws of optics directly into the neural network's mathematical structure.
Consider a standard CNN. It assumes translation invariance: that a feature looks the same regardless of where it appears in the image. That's a useful prior for photographs, but it's a weak prior. It tells the network almost nothing about the physics of your specific imaging modality.
Now consider what we know about microscopy:
- Rotational equivariance: A cell looks the same regardless of its orientation under the objective. Standard CNNs don't know this. They need augmented data to learn it. Our architectures mathematically guarantee it.
- Optical transfer functions: The way light diffracts through a lens is governed by strict wave equations. We encode these equations as structural constraints in the network, so the model inherently understands how a point source gets blurred into an Airy disk.
- Scale consistency: Biological objects at a given magnification have predictable size ranges. We constrain the network's receptive fields to match these physical scales, eliminating entire families of false positives.
This is what we mean by inductive biases. We are not teaching the network about microscopy through data. We are teaching it through architecture.
Self-Supervised Discovery, Not Supervised Memorization
The second half of our approach is equally unconventional. When a client provides us with 1–5 annotated examples, we don't use those examples to fine-tune millions of weights. We use them as semantic anchors in a self-supervised embedding space.
Our foundation models have already been trained, using zero human labels, to understand the structural grammar of biological imagery. They know what constitutes an "object" versus "background" because they've learned to predict optical consistency under computational perturbation (noise, blur, geometric warping). This is the self-supervised paradigm we published in Nature Communications in 2022.
When you give our system 5 labeled cells, it doesn't retrain. It performs a high-dimensional similarity search. The foundation model already knows what objects are. Your 5 examples simply tell it which objects you care about today.
The Result: Data Efficiency That Actually Makes Sense
This is why our approach works with 5 datapoints while a fine-tuned ImageNet model needs 5,000:
| Approach | What 5 examples teach | Data efficiency |
|---|---|---|
| ImageNet fine-tuning | Everything: what a cell is, how light works, what blur means, what the background looks like | Very low-5 examples can't teach all this |
| Domain-specific pre-training | Task-specific features, leveraging related microscopy data | Moderate-but requires massive curated datasets |
| IFLAI (physics + self-supervision) | Only: "this specific morphology is what I'm looking for" | Extreme: the architecture already knows everything else |
The network doesn't need your data to learn physics. Physics was there before the data.
Why This Matters Commercially
For a pharmaceutical company running phenotypic screens, this distinction is the difference between a 3-month AI integration project and a same-day deployment. You don't need to build a training dataset. You don't need to hire an annotation team. You don't need to wait for a model to converge.
You show our system what you're looking for. It finds it. That's not fine-tuning. That's physics.